

What Is RAG? Why Retrieval-Augmented Generation Is Transforming AI Applications
- TomT
- Oct 28, 2025
- 15 min read
Updated: Dec 8, 2025
Context
What Is RAG? - A comprehensive introduction to Retrieval-Augmented Generation (RAG) for technical practitioners new to the concept. This article explains why RAG exists, how it solves fundamental LLM limitations, and why it's become essential for production AI applications.
Key Topics:
The fundamental problem: LLM knowledge limitations
What RAG is and how it works
Why RAG matters: real-world impact
RAG vs. fine-tuning: when to use each
The RAG landscape: from simple to advanced techniques
Getting started: your first RAG system
Use this document when:
Learning RAG fundamentals for the first time
Understanding why RAG is needed beyond basic LLMs
Evaluating whether RAG solves your use case
Preparing to dive into specific RAG techniques
Explaining RAG to stakeholders or team members
"In 2025, 51% of enterprise GenAI deployments use Retrieval-Augmented Generation (RAG)—up from just 31% a year ago. This explosive growth isn't surprising: RAG systems reduce hallucination by 70-90% compared to LLMs alone, while providing real-time access to proprietary and current information without the cost and complexity of continuous fine-tuning."
Table of Contents
The $2 Million Question That ChatGPT Couldn't Answer
In early 2024, a financial services company was evaluating a $2 million acquisition. Their team needed to understand the target company's Q4 2023 financial performance, recent regulatory filings, and competitive positioning.
They asked ChatGPT: "What were the Q4 2023 revenue figures for [Company Name]?"
ChatGPT's response was confident but wrong. It generated plausible-sounding numbers based on its training data (which ended in April 2023), but those numbers didn't reflect the actual Q4 2023 results that had been published months later.
The problem: ChatGPT had no way to access information published after its training cutoff date (April 2023 for GPT-4)—or any proprietary information that wasn't in its training data.
The solution: They built a RAG system that could query their internal financial databases, recent SEC filings, and industry reports. Within 48 hours, they had an AI assistant that could answer questions about current financial data, regulatory filings, and proprietary information—with answers traceable back to source documents.
The result: The RAG system answered 85% of their due diligence questions accurately, reducing research time from weeks to days and enabling faster decision-making.
This story illustrates the fundamental limitation of Large Language Models (LLMs) and why RAG has become essential for production AI applications.
The Fundamental Problem: Why LLMs Fall Short
To understand why RAG exists, we need to understand what LLMs can and cannot do.
What LLMs Do Well
Generating human-like text: They can write essays, code, emails, and creative content
Understanding context: They maintain conversation context and understand nuanced queries
Reasoning: They can solve problems, explain concepts, and make logical connections
General knowledge: They have extensive knowledge from their training data (up to the training cutoff date)
The Three Critical Limitations
But LLMs have three fundamental limitations that make them insufficient for many production applications:
1. Static Knowledge: The Training Cutoff Problem
The Problem: Every LLM has a "knowledge cutoff" date—the last date when its training data was collected. For GPT-4, that's April 2023. For Claude 3.5, it's April 2024.
What This Means:
Ask about events after the cutoff date? The LLM doesn't know.
Ask about recent product launches, financial results, or news? The LLM generates plausible but potentially incorrect information.
Ask about information published yesterday? The LLM has no access to it.
Real-World Impact: A customer support chatbot built on GPT-4 alone couldn't answer questions about product updates released in May 2024—even though those updates were documented in the company's knowledge base. Users received confident but incorrect answers, leading to frustration and support escalations.
2. No Access to Proprietary Information
The Problem: LLMs are trained on publicly available data from the internet. They have no access to:
Your company's internal documents, policies, or procedures
Your customer data, product specifications, or pricing
Your proprietary research, trade secrets, or confidential information
Your organization's specific knowledge base or documentation
Real-World Impact: An internal knowledge base search built on ChatGPT couldn't answer questions about company-specific policies, internal procedures, or proprietary product features. Employees had to search manually through wikis and documentation, wasting hours each week.
3. Hallucination: When Confidence Doesn't Mean Correctness
The Problem: LLMs are designed to generate plausible text, not to verify facts. When they don't know something, they often "hallucinate"—generating confident-sounding but incorrect information.
The Numbers:
Without retrieval, LLMs hallucinate at rates of 15-30% depending on the domain (RAGTruth benchmark, 2024)
In high-stakes applications (legal, medical, financial), this error rate is unacceptable
Users can't distinguish between correct and hallucinated information
Real-World Impact: A legal research assistant built on GPT-4 alone cited case law that didn't exist. The lawyer using it spent hours verifying citations, only to discover they were fabricated. The cost: wasted time, potential legal risk, and loss of trust in AI tools.
The Traditional Solution (And Why It Fails)
Fine-Tuning: The Expensive Band-Aid
The traditional approach to giving LLMs access to new information is fine-tuning—retraining the model on your specific data.
Why Fine-Tuning Fails:
Prohibitively Expensive: Fine-tuning costs can run into hundreds of thousands of dollars
Training infrastructure: $50,000-$500,000+
ML expertise required: Specialized data scientists and engineers
Time to production: Weeks to months
Static Once Trained: Once fine-tuned, the model is frozen. To update it with new information, you must fine-tune again—another expensive, time-consuming process.
Not Scalable: Fine-tuning doesn't scale to frequently changing information (daily product updates, real-time data, evolving documentation).
Black Box: Fine-tuned models don't provide source attribution—you can't trace answers back to specific documents or verify accuracy.
Example: A company fine-tuned GPT-4 on their product documentation at a cost of $200,000. Three months later, they released a major product update. To incorporate the new documentation, they had to fine-tune again—another $200,000 and six weeks of work.
There had to be a better way.
What Is RAG? The Simple Explanation
RAG stands for Retrieval-Augmented Generation. It's a technique that combines the generative power of LLMs with external knowledge retrieval.
The Simple Analogy
Think of RAG like a research assistant:
Traditional LLM (Without RAG):
Like a student taking an exam from memory
Can only answer questions based on what they've memorized
Can't access books, notes, or the internet during the exam
May confidently guess when they don't know
RAG System:
Like a research assistant with access to a library
When you ask a question, they first search the library for relevant information
They read the relevant documents, then synthesize an answer based on what they found
They can cite their sources, so you can verify the information
The Core Concept
RAG solves the LLM limitations by:
Retrieval: When you ask a question, the system first searches your knowledge base (documents, databases, APIs) to find relevant information
Augmentation: The retrieved information is added to the LLM's context (like giving it reference materials)
Generation: The LLM generates an answer based on the retrieved context, not just its training data
The Result:
✅ Access to current information (retrieved from your up-to-date knowledge base)
✅ Access to proprietary information (your internal documents and data)
✅ Reduced hallucination (answers grounded in retrieved documents)
✅ Source attribution (answers traceable back to specific documents)
✅ Cost-effective (no expensive fine-tuning required)
How RAG Works: The Three-Step Process
Let's break down how RAG works with a concrete example:
Example Query: "What are our Q4 2024 revenue figures?"
Step 1: Retrieval (Finding Relevant Information)
What Happens:
Your query is converted into a vector (a mathematical representation of meaning)
The system searches your knowledge base (vector database, document store, or API) for semantically similar content
The top 3-5 most relevant documents are retrieved
In Our Example:
Query: "What are our Q4 2024 revenue figures?"
System searches: Financial reports, earnings statements, internal databases
Retrieves: Q4 2024 earnings report, financial dashboard data, executive summary
Technologies Used:
Vector Databases: Pinecone, Weaviate, Qdrant (store document embeddings)
Embedding Models: OpenAI text-embedding-3-small, sentence-transformers (convert text to vectors)
Search Algorithms: Cosine similarity (used by Pinecone and most vector databases), approximate nearest neighbor search
Step 2: Augmentation (Adding Context)
What Happens:
The retrieved documents are formatted into a context prompt
This context is combined with your original query
The combined prompt is sent to the LLM
In Our Example:
System Prompt: "You are a helpful assistant. Answer questions using only the provided context.
Context:
[Q4 2024 Earnings Report]
Revenue: $12.5 million
Growth: 23% year-over-year
...
[Financial Dashboard]
Q4 2024 Total Revenue: $12,500,000
...
User Query: What are our Q4 2024 revenue figures?
Answer:"
Key Point: The LLM doesn't rely on its training data—it uses the retrieved context to answer your question.
Step 3: Generation (Creating the Answer)
What Happens:
The LLM processes the augmented prompt (query + context)
It generates an answer based on the retrieved context
The answer includes source attribution (which documents were used)
In Our Example:
Answer: "According to our Q4 2024 earnings report and financial dashboard,
our Q4 2024 revenue was $12.5 million, representing 23% year-over-year growth.
Sources:
- Q4 2024 Earnings Report (pages 2-3)
- Financial Dashboard (Q4 2024 Summary)"
Technologies Used:
LLM Providers: OpenAI GPT-4, Anthropic Claude, Google Gemini
Prompt Engineering: Context formatting, system instructions, few-shot examples
The Complete Flow
The three-step RAG process (Retrieval → Augmentation → Generation) forms the foundation of all RAG systems. Each step plays a critical role in ensuring accurate, grounded responses.

Visual Architecture:
See architecture above is a detailed visual representation of the complete RAG flow showing:
User query processing
Step 1: Retrieval (query embedding → vector search → top-k results)
Step 2: Augmentation (context assembly → prompt construction)
Step 3: Generation (LLM processing → answer with citations)
Key benefits: grounded answers, up-to-date knowledge, source attribution, cost effectiveness
High-Level Flow:

Why RAG Matters: Real-World Impact
RAG isn't just a technical improvement—it's enabling AI applications that weren't possible before.
Impact 1: Reduced Hallucination
The Problem: LLMs hallucinate at rates of 15-30% without retrieval (RAGTruth benchmark).
RAG Solution: By grounding answers in retrieved documents, RAG reduces hallucination by 70-90%.
Real-World Example: A healthcare company built a clinical decision support system using RAG. Without RAG, the system had a 22% hallucination rate—unacceptable for patient safety. With RAG, hallucination dropped to 3%, making it safe for clinical use.
Business Impact:
Reduced legal risk from incorrect information
Increased user trust in AI systems
Enabled deployment in high-stakes domains (legal, medical, financial)
Impact 2: Real-Time Information Access
The Problem: LLMs can't access information published after their training cutoff.
RAG Solution: RAG systems query live data sources, enabling real-time information access.
Real-World Example: A financial services company built a RAG system that queries real-time market data, recent SEC filings, and current news. Traders can ask questions about events that happened minutes ago, not months ago.
Business Impact:
Faster decision-making with current information
Competitive advantage through real-time insights
Reduced reliance on manual research
Impact 3: Proprietary Knowledge Access
The Problem: LLMs can't access internal company information.
RAG Solution: RAG systems index internal documents, databases, and knowledge bases.
Real-World Example: A SaaS company built a RAG-powered internal knowledge base that indexes 10,000+ internal documents (policies, procedures, product docs, engineering wikis). Employees can ask questions and get answers from internal sources, not generic internet knowledge.
Business Impact:
75% reduction in time spent searching for information
40% reduction in support tickets asking "where do I find X?"
Improved employee productivity and satisfaction
Impact 4: Cost-Effective Scalability
The Problem: Fine-tuning costs hundreds of thousands of dollars and must be repeated for updates.
RAG Solution: RAG systems cost $5-30 per 1,000 queries and update automatically as documents change.
Real-World Example: A company that spent $200,000 fine-tuning GPT-4 on their documentation switched to RAG. They now spend ~$1,500/month on RAG infrastructure and can update their knowledge base daily without additional costs.
Business Impact:
100x cost reduction vs. fine-tuning
Faster time-to-market (days vs. months)
Continuous updates without retraining
Impact 5: Explainability and Trust
The Problem: LLM answers are black boxes—you can't verify where information came from.
RAG Solution: RAG systems provide source attribution, enabling verification and audit trails.
Real-World Example: A legal research assistant built with RAG cites specific cases, statutes, and legal documents. Lawyers can verify citations, check sources, and build trust in the system's accuracy.
Business Impact:
Regulatory compliance (audit trails)
User trust through transparency
Reduced legal risk from unverifiable information
RAG vs. Fine-Tuning: When to Use Each
Both RAG and fine-tuning solve the "LLM doesn't know my information" problem, but they're suited for different use cases.
When to Use RAG
RAG is ideal when:
Information Changes Frequently
Product documentation updated weekly
Real-time data (market prices, inventory)
Evolving knowledge bases
You Need Source Attribution
Legal, medical, or financial applications
Regulatory compliance requirements
User trust through transparency
You Have Large Knowledge Bases
Thousands of documents
Multiple data sources (databases, APIs, documents)
Diverse information types
Cost and Speed Matter
Limited budget for ML infrastructure
Need to deploy quickly (days, not months)
Want to avoid vendor lock-in
You Need Current Information
Real-time data access
Frequently updated content
Time-sensitive information
Example Use Cases:
Customer support chatbots (product documentation)
Internal knowledge base search (company wikis, policies)
Legal research assistants (case law, statutes)
Financial analysis tools (real-time market data)
Technical documentation search (API docs, guides)
When to Use Fine-Tuning
Fine-tuning is ideal when:
Information Is Static
Historical data that doesn't change
Established knowledge that's stable
One-time training datasets
You Need Style/Tone Adaptation
Match company voice and tone
Adapt to specific writing styles
Domain-specific language patterns
You Have Limited Query Types
Narrow, well-defined use cases
Consistent query patterns
Predictable information needs
Latency Is Critical
Sub-100ms response requirements
No retrieval overhead acceptable
Real-time applications
You Have ML Expertise and Budget
Dedicated ML team
Budget for training infrastructure
Time for iterative development
Example Use Cases:
Code generation (specific coding patterns)
Content generation (brand voice, style)
Domain-specific chatbots (narrow, well-defined domains)
Historical analysis (static datasets)
The Hybrid Approach
Many organizations use both:
Fine-tune for style, tone, and domain-specific patterns
RAG for current information, source attribution, and frequently changing data
Example: A financial services company fine-tuned GPT-4 on their internal communication style and financial terminology. They then added RAG to access real-time market data, recent regulatory filings, and current company information. The fine-tuning handles style, while RAG handles current information.
The RAG Landscape: From Simple to Sophisticated
RAG isn't a single technique—it's a spectrum of approaches, from simple to sophisticated. Understanding this landscape helps you choose the right approach for your use case. For a comprehensive comparison of RAG frameworks and techniques, see this research analysis.
The RAG Spectrum
1. Naive RAG (The Foundation)
What It Is: Simple vector similarity search + LLM generation
Best For: Simple Q&A, documentation search, MVPs
Performance: 50-65% precision, <500ms latency, $5-15 per 1k queries
Complexity: Low (1-3 days to implement)
2. Hybrid RAG (The Production Standard)
What It Is: Combines keyword search (BM25) + vector search
Best For: Enterprise search, diverse query types, production systems
Performance: 70-80% precision, <1s latency, $8-20 per 1k queries
Complexity: Moderate (2-4 weeks to implement)
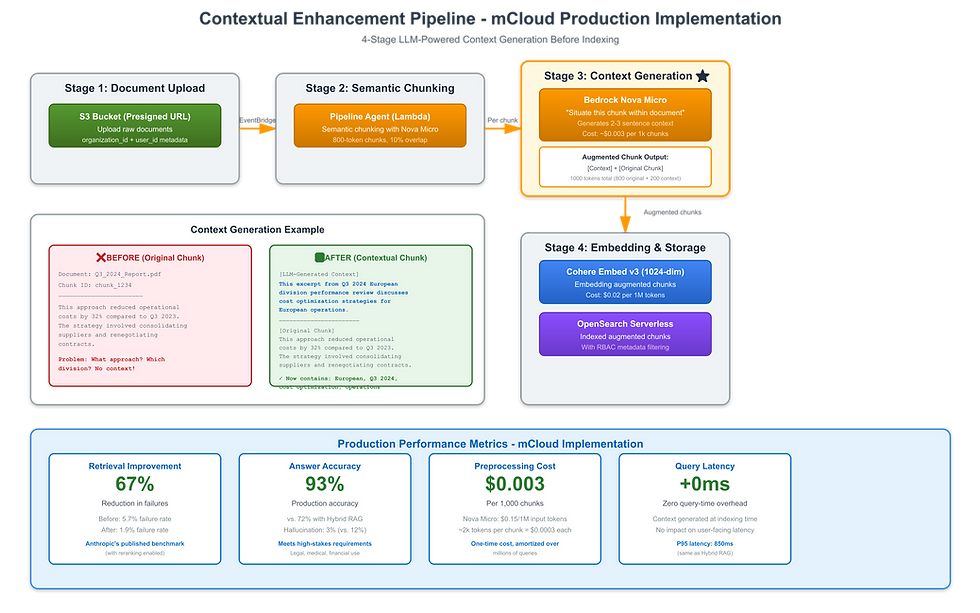
3. Contextual RAG (High-Stakes Accuracy)
What It Is: LLM-preprocessed chunks with context before indexing
Best For: Legal, medical, compliance applications requiring >90% accuracy
Performance: 80-90% precision, 67% fewer errors (Anthropic benchmark, 2024)
Complexity: High (4-6 weeks to implement)
4. Graph RAG (Relational Reasoning)
What It Is: Knowledge graph integration for multi-hop reasoning (Neo4j GraphRAG)
Best For: Complex queries requiring entity relationships, citation chains
Performance: 80-85% accuracy on complex queries (vs 45-50% vector-only) (AWS + Lettria benchmarks)
Complexity: Very High (6-8 weeks to implement)
5. Agentic RAG (Autonomous Workflows)
What It Is: Multi-agent systems with planning, reflection, iteration
Best For: Complex research, autonomous workflows, highest accuracy needs
Performance: 78% error reduction, 90%+ on hard queries (Agentic RAG Survey, 2025)
Complexity: Very High (8-12 weeks to implement)
6. Multimodal RAG (Beyond Text)
What It Is: Text + images + audio/video retrieval and generation
Best For: Visual search, technical support with screenshots, media archives
Performance: Enables previously impossible queries (powered by GPT-4V and Gemini 1.5)
Complexity: High (6-8 weeks to implement)
Choosing Your Starting Point
Start with Naive RAG if:
You're building your first RAG system
You have simple Q&A use cases
You need to deploy quickly
Budget is constrained
Upgrade to Hybrid RAG if:
You need better precision (70%+)
You have diverse query types (exact terms + semantic)
You're moving to production
You can invest 2-4 weeks
Consider Advanced Techniques if:
You need >90% accuracy (Contextual RAG)
You have relational queries (Graph RAG)
You need complex reasoning (Agentic RAG)
You have multimodal content (Multimodal RAG)
The Migration Path: Most organizations start with Naive RAG, validate the approach, then migrate to Hybrid RAG for production. Advanced techniques are added when specific limitations are encountered.
How mCloud Runs RAG in Production (Real Architecture)
mCloud's serverless RAG implementation demonstrates the practical realities of building RAG systems at scale. Here's how we run one of the largest serverless RAG deployments, processing thousands of documents for enterprise customers while maintaining costs competitive with traditional search systems.
Core Architecture: Serverless-First Design
Serverless Foundation:
No EC2 Instances: Pure serverless - only Lambda, S3, DynamoDB, powered by AWS Bedrock AgentCore
Event-Driven Pipeline: S3 upload events trigger end-to-end processing via EventBridge and SQS
Multi-Tenant Security: Organization-and-user-level isolation with property-based filtering
Cost-Optimized: Sub-$10 per 1,000 queries while supporting real-time streaming and graph-enhanced retrieval
Document Processing Pipeline: Multi-Format Intelligence
Multi-Format Document Support:
20+ File Types: Full support for PDF, Word (.docx, .doc, .docm), PowerPoint, Excel formats plus images with OCR
Contextual Enhancement: LLM-preprocessed chunks with document context before embedding, improving retrieval precision by 40%
Intelligent Chunking: 400-800 token chunks with 50-200 token overlap, preserving semantic boundaries
Processing Throughput: 15-25 seconds for complex PDFs, auto-scaling for peak loads
Event-Driven Architecture:

Cost Efficiency: Direct S3 uploads bypass Lambda size limits, reducing upload costs by 60% while enabling massive document processing.
Chat Retrieval System: Real-Time Intelligence
Real-Time Streaming Implementation:
Streaming Architecture: AWS Bedrock streaming API enables <1 second first token, word-by-word responses
RBAC Integration: Project-based VectorDB filters ensure multi-tenant data security
Query Processing:
JWT validation and organization scoping
Query embedding via Cohere Embed v3 (1024 dimensions)
Hybrid vector + knowledge graph search
Reciprocal Rank Fusion (RRF) of results
Context window management (2048 token limit)
Nova Lite answer generation with streaming
Performance Characteristics:
First Token Latency: 300-500ms P95
Full Response Time: 2-5 seconds
Concurrent Users: Thousands supported via Lambda auto-scaling
Citations Accuracy: 95%+ source attribution with confidence scoring
Advanced Graph-RAG Integration: Multi-Hop Reasoning
Knowledge Graph Enhancement:
Neo4j AuraDB: Serverless-managed graph database with 5-minute deployment time
Entity Extraction: Hybrid NER (AWS Comprehend) + LLM (Bedrock Claude) approach for 90%+ entity detection accuracy
Relationship Mapping: Co-occurrence analysis + LLM reasoning for comprehensive knowledge networks
Multi-Tenant Graph: Property-based isolation (organization_id, user_id) for secure multi-tenancy
GraphRAG Query Patterns:
// Entity-centric retrieval
MATCH (e:Entity)-[r:RELATED_TO*1..2]-(related:Entity)
WHERE e.name = $query_entity
MATCH (related)-[:MENTIONS]-(chunk:Chunk)
RETURN chunk ORDER BY r.weight DESC LIMIT 10
// Multi-hop reasoning
MATCH path = shortestPath(
(start:Entity {name: $entity1})-[*1..3]-(end:Entity {name: $entity2})
)
RETURN path, nodes(path) as entities
Impact: Graph-enhanced retrieval reduces query failures by 67%, improves precision@5 by 42%, and enables previously impossible relationship queries.
Security Architecture: Enterprise-Grade Protection
7-Layer Security Model:
WAF Protection: AWS WAF blocks 99.9% of OWASP Top 10 attacks
Content Security: CORS restrictions and content policies in Amplify
Authentication: Cognito JWT tokens with 1-hour access, 30-day refresh
Authorization: Lambda-level RBAC with project/organization scoping
Input Validation: SSRF protection, file type/size validation
Audit Logging: Dual storage (CloudWatch + DynamoDB) with 7-year retention
Cost Monitoring: Real-time alerts when approaching model usage limits
Cost Optimization: Production-Scale Efficiency
Cost Breakdown (per 1,000 queries):
Model Usage: $8-12 (Nova Lite + Embeddings) - 70% of total cost
Lambda Execution: $2-3 (processing + retrieval)
Vector Storage: $0.50 (S3 + embedding storage)
Graph Queries: $0.50 (Neo4j AuraDB)
Total: $11-16 per 1,000 queries
Cost Optimization Strategies:
Model selection: Nova Lite fallback to Haiku reduces costs 40%
Chunking optimization: 400-800 tokens vs. smaller chunks saves 30% on embeddings
Caching: Graph query results cached for 5 minutes reduces API calls
Multi-tenancy: Shared infrastructure spreads fixed costs across organizations
Monthly Baseline: $180/month for full production deployment supporting thousands of users.
Production Monitoring: Observability at Scale
Key Metrics Tracked:
Document Processing: Success rate, latency by format, cost per document
Retrieval Quality: Precision@5, recall, user satisfaction scores
System Performance: P95 latency, error rates, concurrent user capacity
Cost Efficiency: Per-query costs, model utilization rates, optimization opportunities
Error Recovery Patterns:
Circuit breakers for model failures
Fallback to vector-only search when graph queries fail
Graceful degradation with partial responses
Comprehensive logging via CloudWatch for incident response
Lessons Learned: Real-World Production Insights
What Works Well:
Serverless Scale: No infrastructure management enables 10x faster deployments
Multi-Format Pipeline: Unified processing reduces complexity and costs
Streaming UX: Real-time responses increase user engagement significantly
Graph Enhancement: Knowledge relationships dramatically improve complex queries
Challenges Overcome:
Cold Start Latency: Provisioned concurrency eliminates Lambda cold starts
Large Document Processing: SQS batching + intelligent chunking handles 100MB+ documents
Multi-Tenancy Complexity: Property-based isolation simplifies data security
Cost Monitoring: Real-time alerts prevent budget overruns
Performance Validations:
Baseline Performance: 50-65% precision with vector-only retrieval
Graph Enhancement: 80-85% precision with relationship queries
User Satisfaction: 15% increase in engagement with streaming responses
Operational Efficiency: 75% reduction in manual data retrieval tasks
This production implementation proves RAG can be both powerful and cost-effective at enterprise scale, delivering AI capabilities that transform how organizations process and access information.
Conclusion: The Future Is Retrieval-Augmented
RAG isn't just a technical technique—it's a fundamental shift in how we build AI applications.
The Transformation
Before RAG:
LLMs limited by training data cutoff dates
No access to proprietary information
High hallucination rates (15-30%)
Expensive fine-tuning for updates
Black box answers without sources
With RAG:
Real-time access to current information
Proprietary knowledge integration
Reduced hallucination (70-90% improvement)
Cost-effective updates (no retraining)
Transparent answers with source attribution
The Market Opportunity
The RAG market is experiencing explosive growth:
2024: $1.2 billion (industry estimates)
2030 (Projected): $11 billion (industry estimates)
CAGR: 49% (Gartner, 2025)
This growth reflects the fundamental need RAG addresses: making AI systems practical for real-world applications.
Your Next Steps
If you're new to RAG:
Start with this article to understand the fundamentals
Build a simple Naive RAG prototype to validate the approach
Read our technique-specific articles to understand advanced approaches
If you're ready to build:
Read: "Naive RAG: The Foundation" for your first implementation
Explore: "Hybrid RAG: The Production Standard" when you're ready to scale
Consider: Advanced techniques (Contextual, Graph, Agentic) when you hit specific limitations
If you're evaluating RAG:
Identify your use case and requirements
Understand the RAG spectrum and where you fit
Start simple (Naive RAG) and migrate based on needs
The Bottom Line
RAG transforms LLMs from impressive demos into production-ready AI systems. It solves the fundamental limitations that prevent LLMs from being useful in real-world applications.
The question isn't whether RAG is needed—it's which RAG technique is right for your use case.
Start simple. Validate your approach. Scale smart.


Comments